Mistral AI Integration
Drop-in wrapper for the Mistral AI SDK. Traces Mistral Large, Small, Mixtral, and all Mistral models with token usage and cost per call.
Mistral AI provides high-performance language models (Mistral Large, Mistral Small, Mixtral, Codestral) via API, optimized for efficiency and reasoning.
zespan.com — mistral ai trace
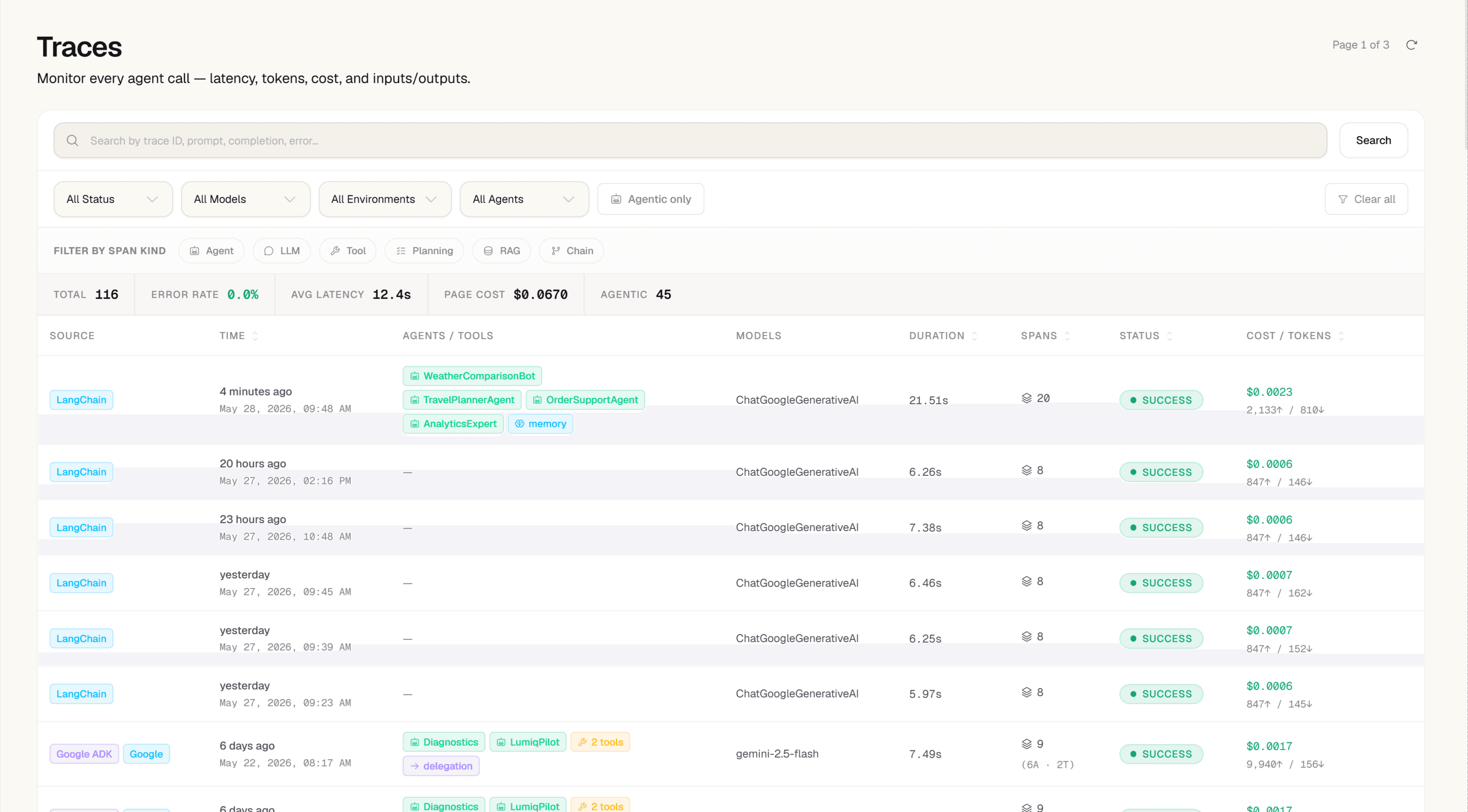
Getting Started
1
Install the SDK
Install @zespan/sdk alongside @mistralai/mistralai.
bash
npm install @zespan/sdk @mistralai/mistralai2
Wrap the Mistral client
Pass your Mistral client to wrapMistral(). All chat complete and embedding calls are traced.
typescript
import { Mistral } from '@mistralai/mistralai';
import { Zespan, wrapMistral } from '@zespan/sdk';
const lt = new Zespan({ apiKey: process.env.ZESPAN_API_KEY });
const mistral = wrapMistral(
new Mistral({ apiKey: process.env.MISTRAL_API_KEY }),
lt
);
const response = await mistral.chat.complete({
model: 'mistral-large-latest',
messages: [{ role: 'user', content: 'Hello' }],
});3
View traces in Zespan
Open Trace Explorer. Mistral calls appear with model, token usage, cost, and latency.
What's captured automatically
- All Mistral models: Mistral Large, Small, Mixtral, Codestral, Pixtral
- Function calls: tool invocations captured as child spans
- Streaming: time-to-first-token measured for streaming completions
- Cost comparison: compare Mistral Large vs Small vs Mixtral in Cost Attribution
- JSON mode: structured output compliance visible per response
FAQ
Does this work with Mistral's function calling?
Yes. Mistral function calls are captured as child spans with arguments and results, same as OpenAI tool calls.
Start for free — 10K traces/month, no card needed
Mistral AI integration works on all plans including the free tier.