Feature — Agent Monitoring
Know which agents are healthy — and which aren't.
Composite health scores, delegation graphs, and per-agent cost attribution — built for systems with many cooperating AI agents.
Works with LangChain, CrewAI, AutoGen, Google ADK, and any framework using the SDK.
A–F
health grades
0–100
composite score
3 signals
error · cost · eval
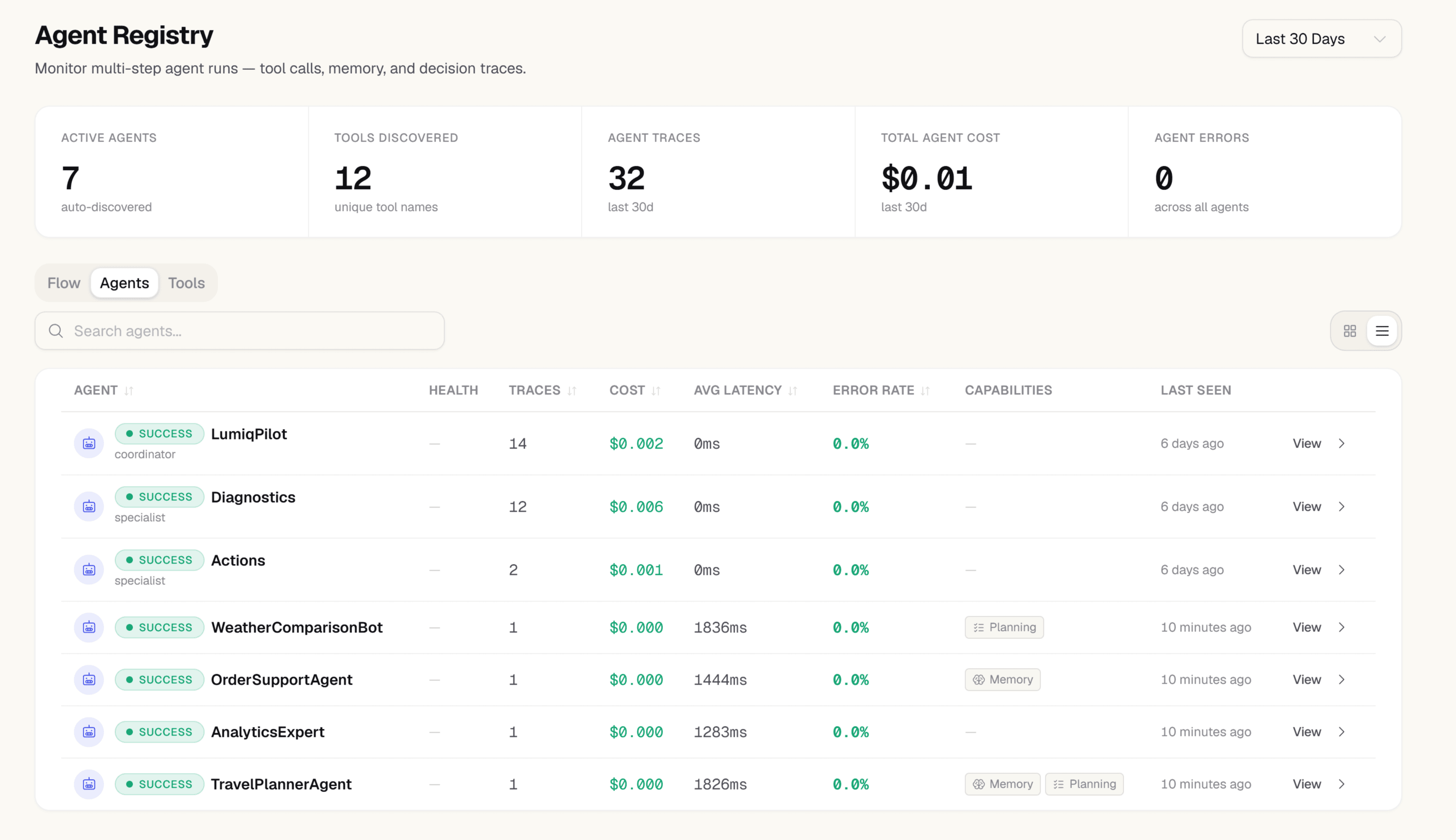
Agent Registry — zero config
Every agent that touches the SDK appears in the Agent Registry on its first run. Name, role, and framework are detected from span attributes automatically — no registration step, no YAML config.
- Auto-discovery: agent_name, agent_role, agent_framework detected from span attributes
- Full inventory: all agents active in a project with framework and call counts
- Supports LangChain, CrewAI, AutoGen, Google ADK, and custom agents
Composite Health Score
Every agent gets a 0–100 score graded A–F, weighted across three signals. If an agent starts degrading — error rate creeping up, cost trending higher, eval scores slipping — the health score reflects it before users notice.
- Error rate: last 24 hours — 40% weight
- Cost trend: week-over-week change — 30% weight
- Eval pass rate: last 7 days — 30% weight
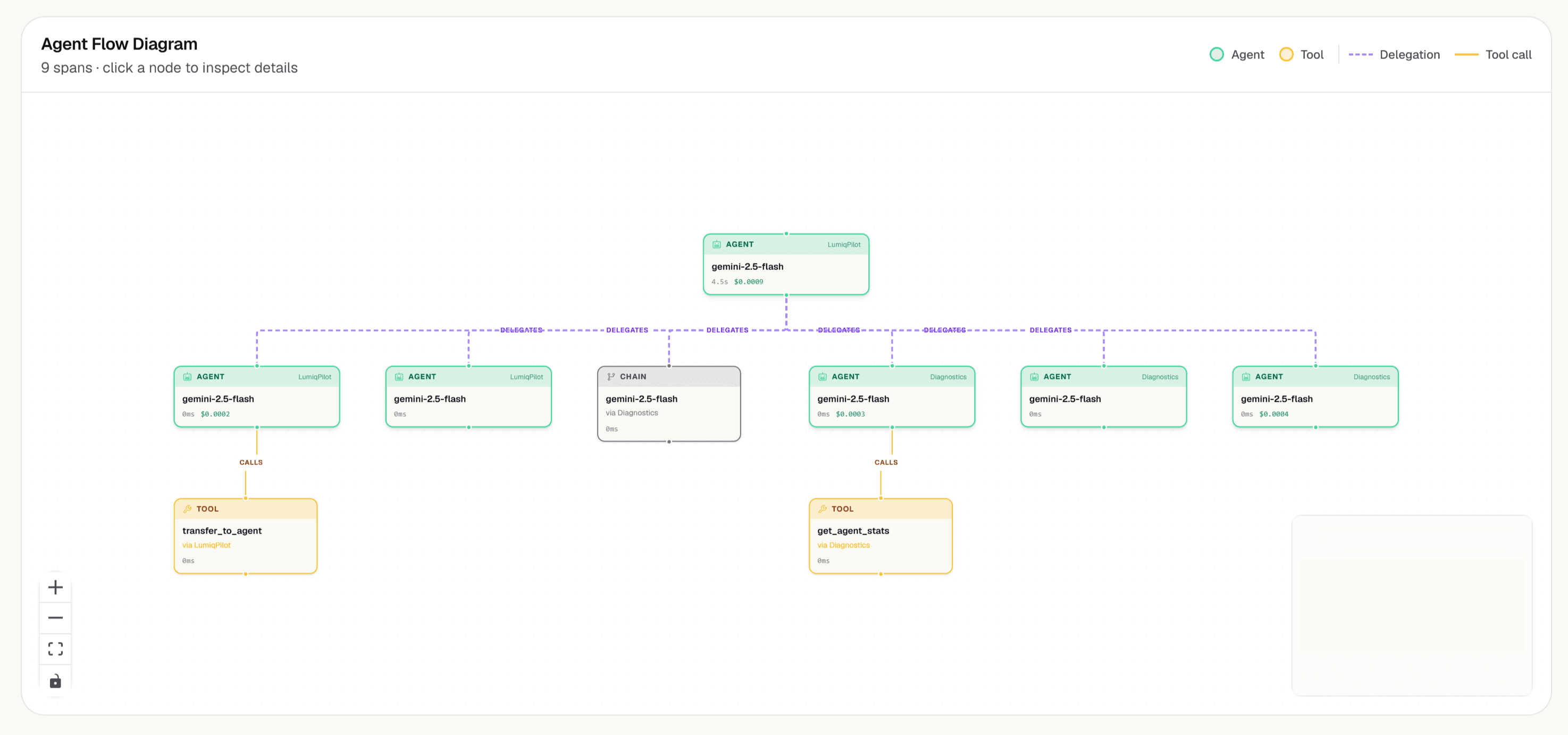
Delegation Graph
Visualizes which agents delegate to which other agents — cost and latency per handoff edge. Understand the coordination topology of your multi-agent system and pinpoint where time and money accumulate.
- Per-hop attribution: cost, latency, and token counts per delegation edge
- Derived from delegated_to / delegated_from span attributes automatically
- Planning step sequences captured per agent for reasoning analysis
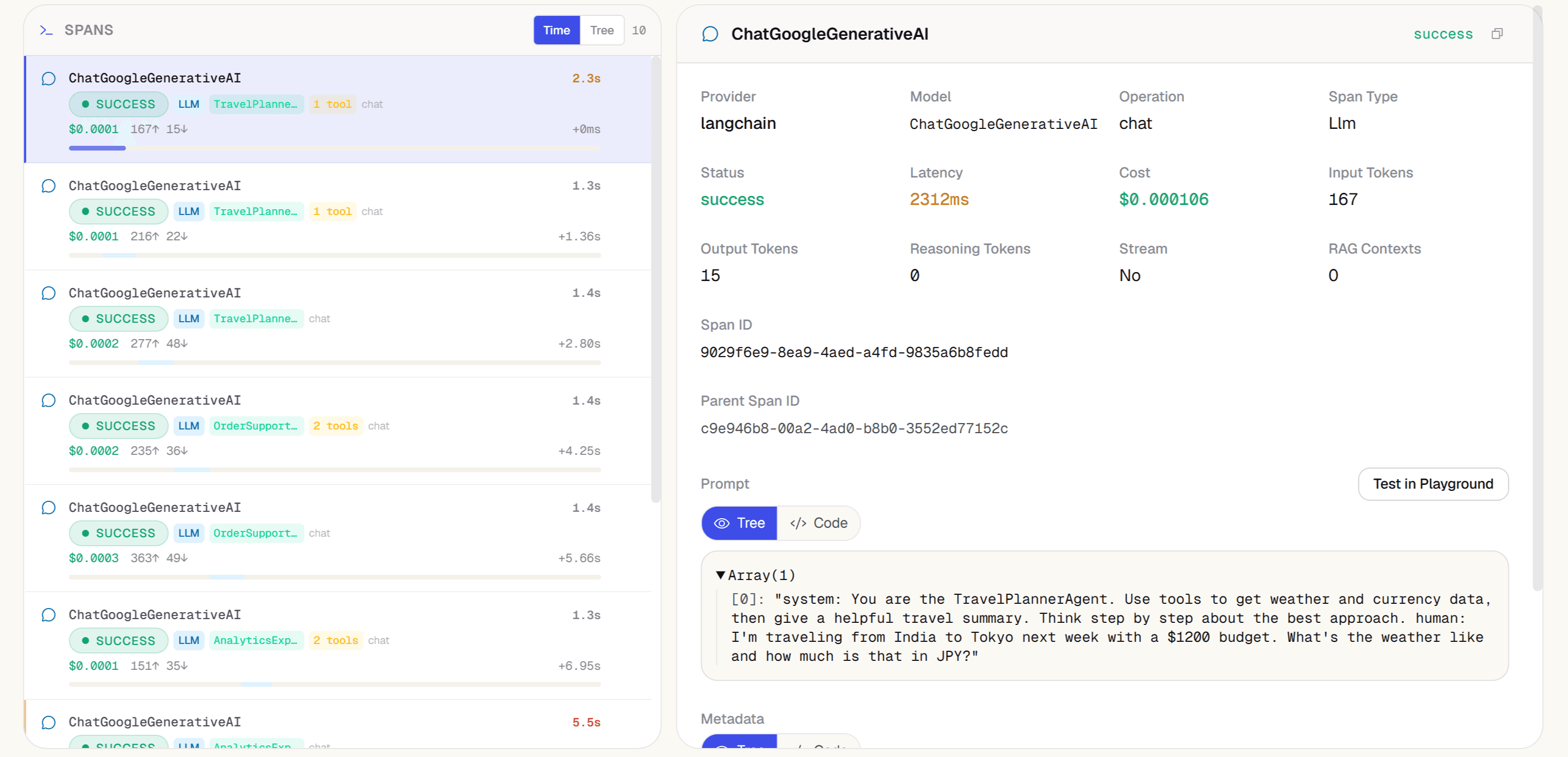
Per-Agent Analytics
Drill into any agent to see its full metrics in time-series: LLM calls, tool calls, planning steps, delegations, guardrail checks, total cost, latency, token counts, and error count.
- Tools per agent: which tools called, how often, at what success rate
- Models per agent: which models used across the time window
- Time-series charts: all metrics over configurable time ranges
Get started
Set up in under 5 minutes
import { Zespan, wrapOpenAI } from '@zespan/sdk';
const lt = new Zespan({ apiKey: process.env.ZESPAN_API_KEY });
const openai = wrapOpenAI(new OpenAI(), lt);
// Tag each agent's calls — registry is built automatically
const res = await openai.chat.completions.create({ model: 'gpt-4o', messages }, {
metadata: { agent_name: 'researcher', agent_role: 'retrieval' },
});Frequently asked
How does Zespan know which agent made a call?
You pass agent_name and agent_role in the metadata when calling the SDK wrapper. Zespan reads these from span attributes and groups all calls under that agent. For framework integrations like LangChain or CrewAI, the callback handler injects these automatically.
What frameworks does agent monitoring support?
LangChain, LangGraph, CrewAI, AutoGen, Google ADK, PydanticAI, LlamaIndex, and any custom agent using the SDK or OpenTelemetry. If your agent makes LLM calls through any of the supported providers, it's monitored.
How is the health score calculated?
It's a weighted composite of three signals: error rate over the last 24 hours (40%), cost trend week-over-week (30%), and eval pass rate over the last 7 days (30%). The score updates in real time as new traces arrive.
Can I set alerts based on agent health?
Yes. You can set alert rules on error_rate for a specific agent's spans, or link an alert to an evaluation metric key. When the score crosses your threshold, Zespan notifies you via email, Slack, PagerDuty, or webhook.
Start free — 10K traces/month, no card needed
Setup takes under 5 minutes. Works with OpenAI, Anthropic, LangChain, and more.