Use Case — RAG
Find where your RAG pipeline breaks — retrieval, reranking, or synthesis.
Hallucinations don't appear from nowhere. They come from bad retrievals, ignored context, or prompts that drift. Zespan shows you exactly which step is failing.
The problem
Hallucinations with no trail
You can see a bad output but not the retrieved context that caused it. Was it a poor retrieval, a bad prompt, or the model ignoring context? You can't tell.
Retrieval quality is a black box
You don't know your average retrieval score, how many chunks are retrieved, or whether reranking actually improves results at scale.
Quality degrades silently
Faithfulness scores slip as your document base grows or prompts change. You find out from user reports, not metrics.
How to use Zespan for this
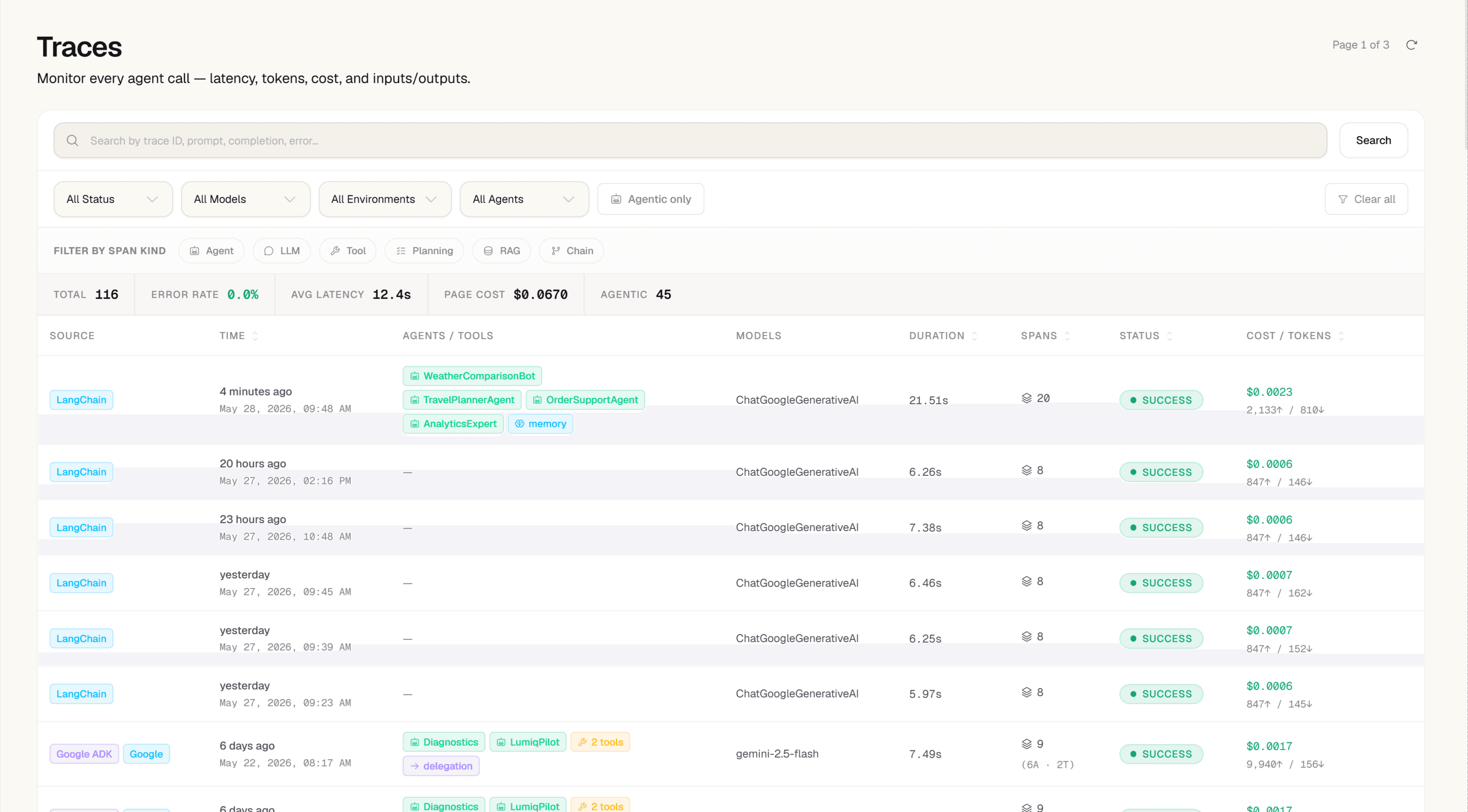
Open Trace Explorer — see every RAG pipeline run
In Trace Explorer, filter by operation=rag or by the model your pipeline uses. Every pipeline run is a trace. Click any one to open the span waterfall — query encoding, vector retrieval, reranking, and LLM synthesis each appear as a separate timed span.
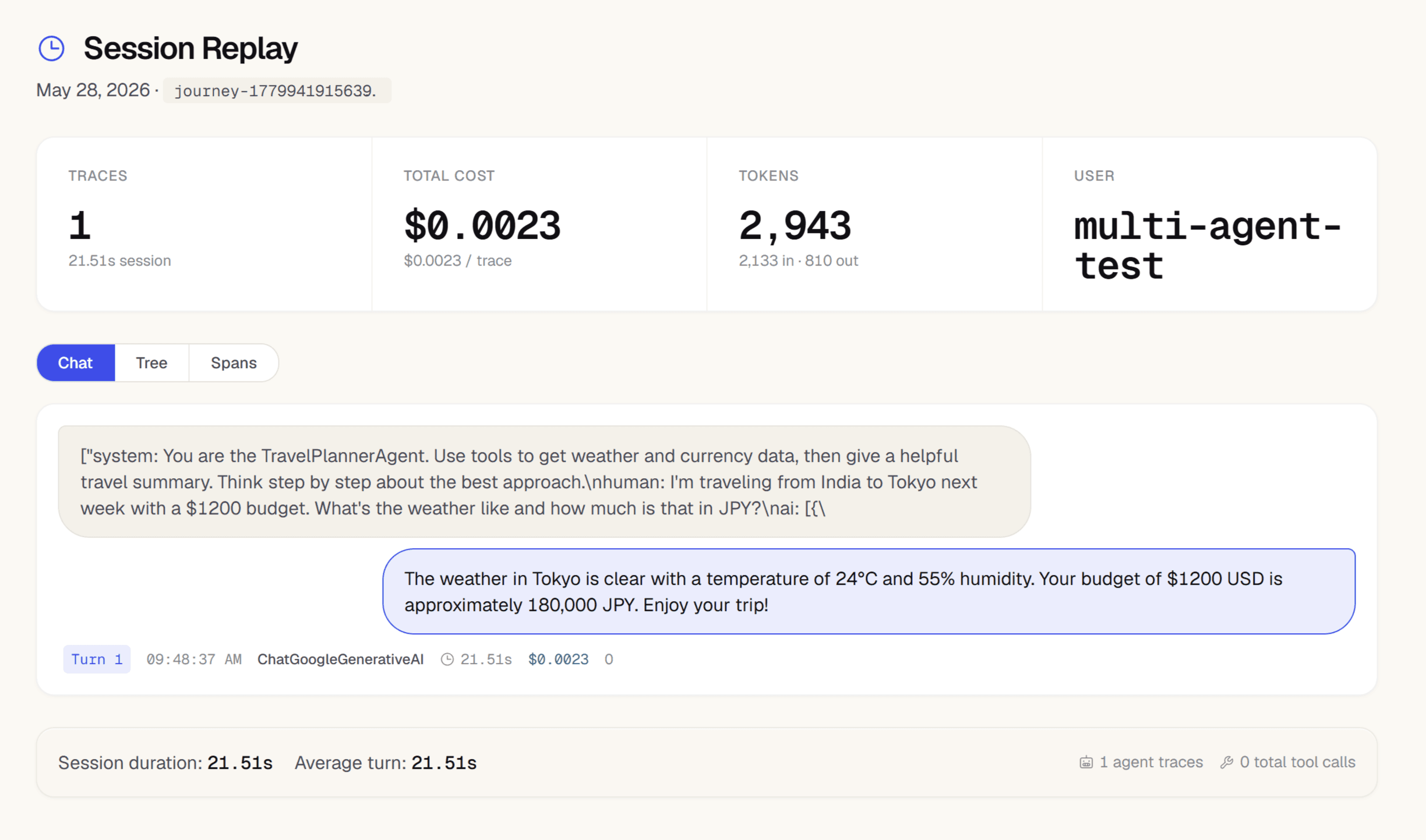
Inspect the span waterfall — see retrieval vs synthesis split
In the span detail view, the waterfall breaks your pipeline into steps. You can see if retrieval is taking 800ms while synthesis takes 200ms, or vice versa. Check retrieved chunk counts and scores per retrieval span to identify when low-score chunks enter the context window.
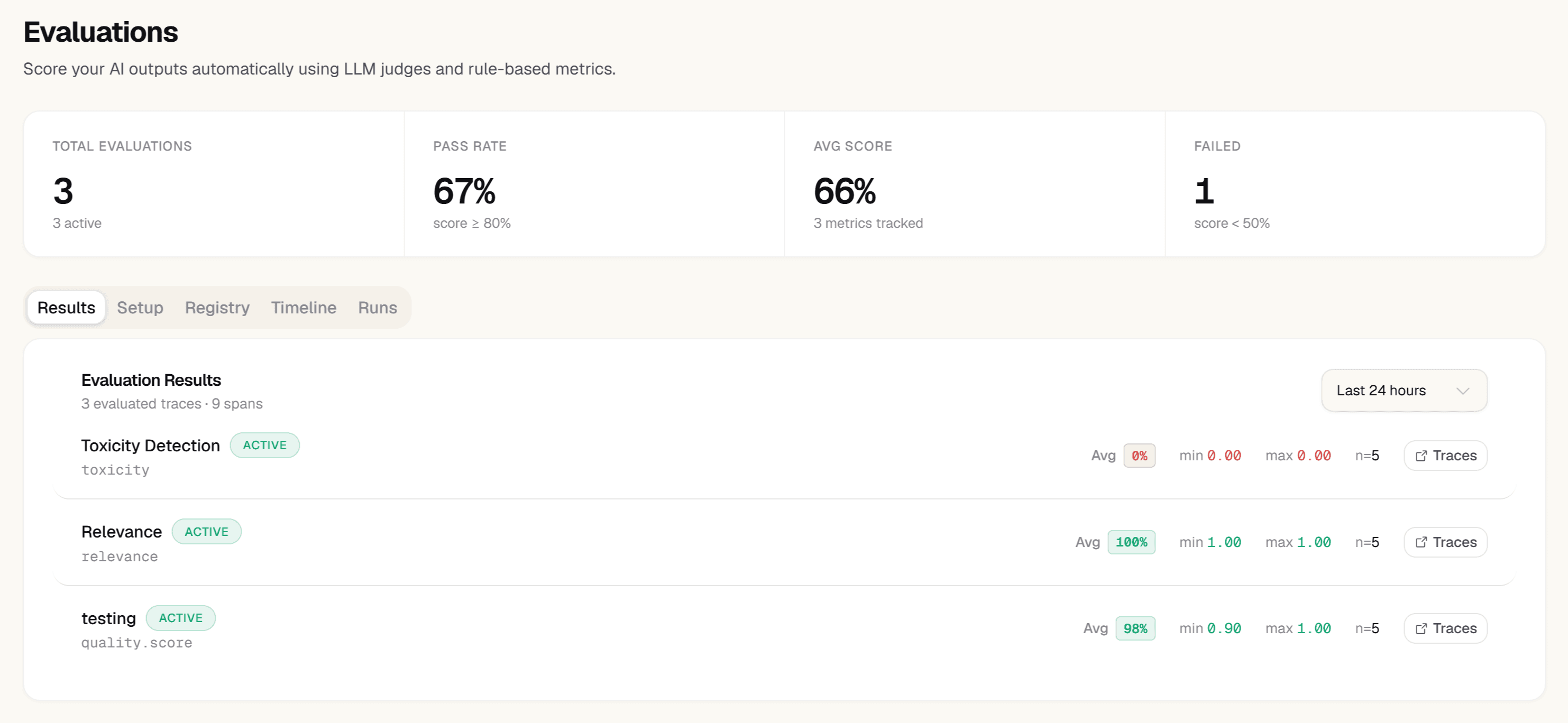
Check Evaluations — faithfulness on every response
Open Evaluations. If you've enabled the faithfulness auto-evaluator, every RAG response has a score: 1.0 means the answer is fully grounded in retrieved context; 0.0 means it came from model memory. Filter to faithfulness < 0.7 to find the responses where the model hallucinated.
Click into failing evaluations — trace the bad retrieval
In the evaluation detail view, click any low-faithfulness trace. You'll see the user question, the retrieved chunks, the synthesized answer, and the judge's reasoning. The gap between the retrieved context and the answer tells you exactly what broke — bad retrieval, low-quality chunks, or the model ignoring context.
Add failing traces to a dataset — regression tests from real failures
Found a trace where retrieval went wrong? Click 'Add to dataset'. Build a dataset of real failures. Next time you change your retrieval config or prompt, run a batch simulation against this dataset — assertions catch regressions before any user sees them.

Start free — 10K traces/month, no card needed
See every agent decision, tool call, and handoff in production. Setup takes under 5 minutes.
Get started free →