Use Case — Eval & Regression
Ship prompt changes without breaking what's already working.
A prompt change fixed one thing and broke another. Without automated eval coverage, you find out from users. Here's how Zespan catches regressions before they reach production.
The problem
Prompt changes break things invisibly
You fixed one output issue and introduced another. You have no automated eval coverage. User feedback is your monitoring.
No quality signal at scale
Manual review covers a dozen traces per sprint. Thousands of production responses go unscored. Quality drift is invisible.
No regression test for prompts
Software teams have CI/CD pipelines. Prompt changes ship to production with no equivalent safety net.
How to use Zespan for this
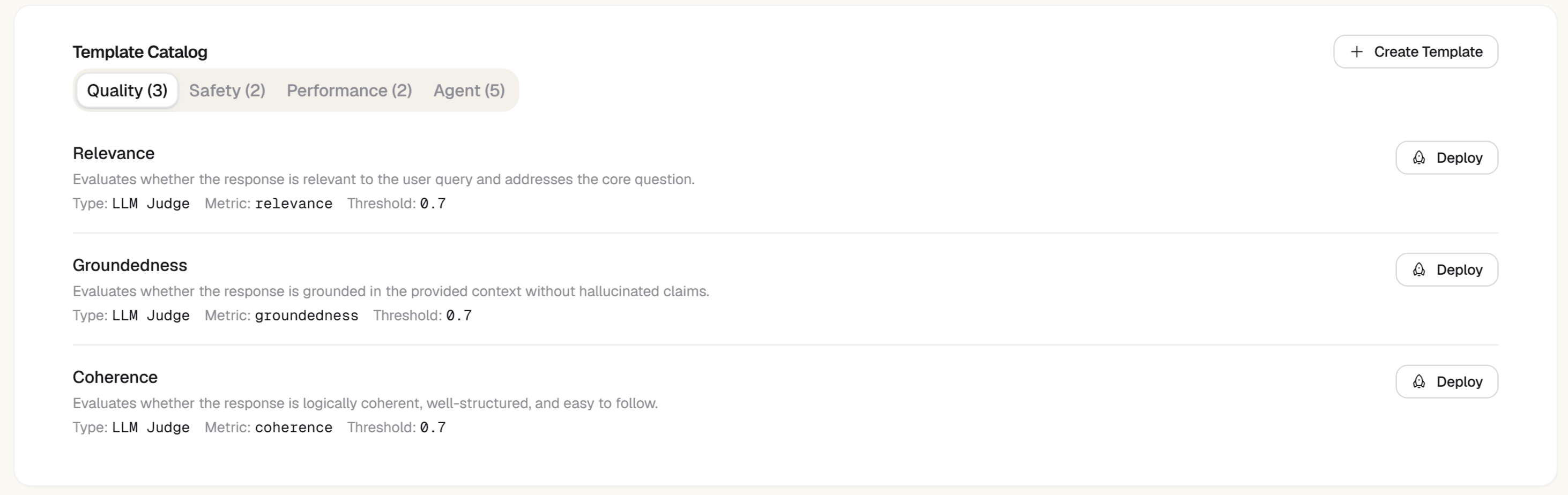
Enable auto-evaluators — quality score on every trace
Go to Project Settings → Evaluations → Auto-Evaluators. Turn on correctness, faithfulness, and any other templates relevant to your output. Set sample rate to 1.0. From this point, every new trace gets scored automatically — no manual work, no cron job. The Evaluations view shows quality trending over time.
Promote a prompt version — regression check runs automatically
In Prompt Management, click 'Promote to production' on your new version. Zespan immediately queues a background regression check: it compares eval scores for the new version against the previous 14 days. If any evaluator drops more than 10 percentage points, you get a ZespanPilot notification before full traffic hits.

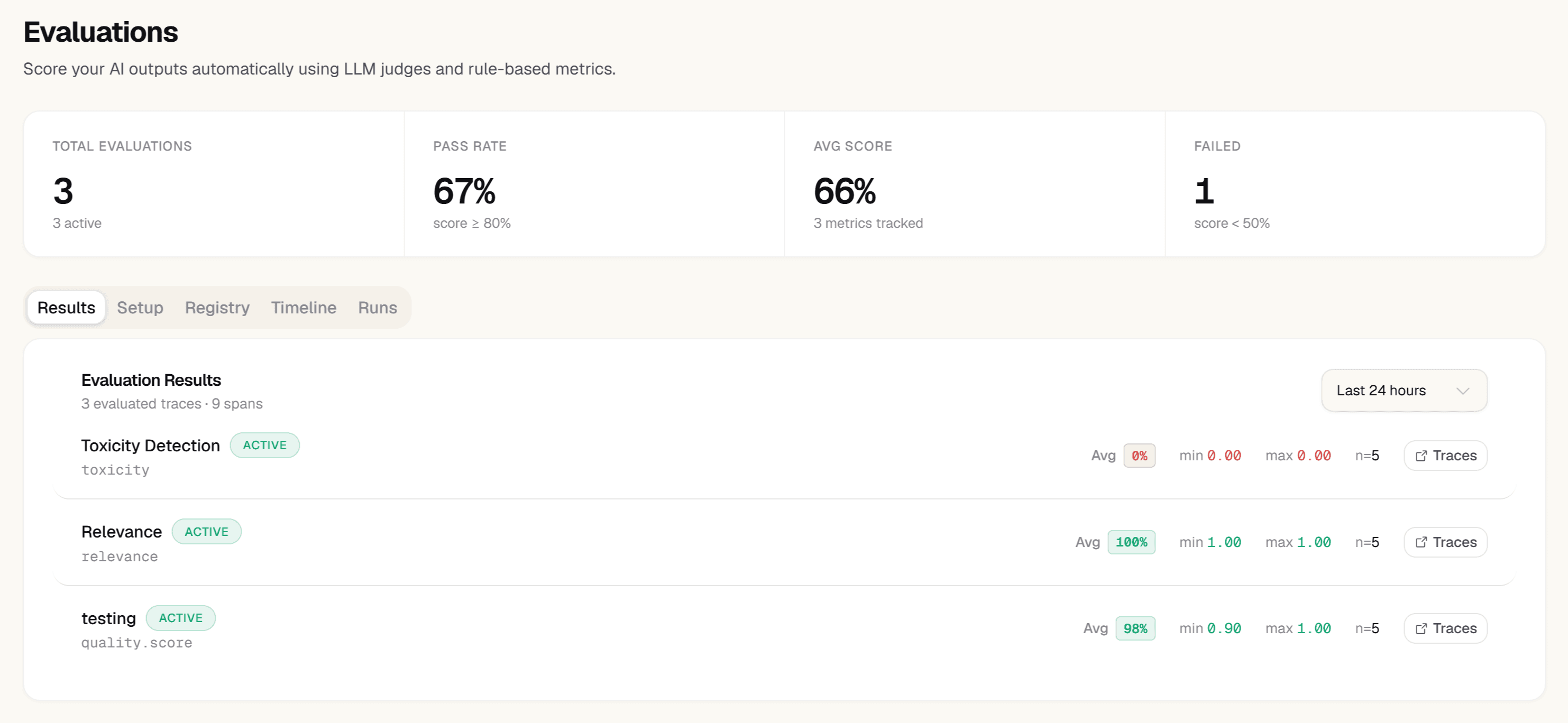
Review evaluation detail — see exactly what changed
Open Evaluation → Detail. Filter by prompt version to compare quality before and after the promotion. Click any low-scoring trace to see the input, output, and judge reasoning. 'The answer contradicts the retrieved context' tells you more than a 0.4 score alone.
Build a dataset from production failures
In Trace Explorer, filter to the traces that scored worst. Select them and click 'Add to dataset'. Name the dataset 'regression-suite'. This is your test harness — built from real production failures, not hypothetical inputs. It grows every time something goes wrong.

Run a batch simulation before next deploy
In Simulations, create a prompt scenario pointing at your regression dataset. Before the next prompt change ships, run a batch. Configure per-scenario assertions — correctness > 0.8, no toxicity, response contains the expected answer structure. Failed assertions block the deploy. That's your LLM CI pipeline.

Start free — 10K traces/month, no card needed
See every agent decision, tool call, and handoff in production. Setup takes under 5 minutes.
Get started free →