Feature — Evaluations
Measure output quality on every trace — automatically.
12 built-in LLM-as-judge templates run on every new trace with no setup. Track quality trends, catch regressions, and run manual eval campaigns.
Auto-evaluators, LLM judge, manual runs, metric timelines — on every plan.
12
built-in templates
200
metric keys
0–1
sample rate
Auto-Evaluators
Enable auto-evaluators in project settings and every new trace gets scored automatically — no manual trigger. Configure sample rate (0–1) for high-volume projects and filter to specific models, operations, or statuses.
- Runs on every new trace — zero manual work after initial config
- Sample rate: evaluate 100% or a fraction of traffic
- filterModels, filterOps, filterStatuses: scope to where quality matters most
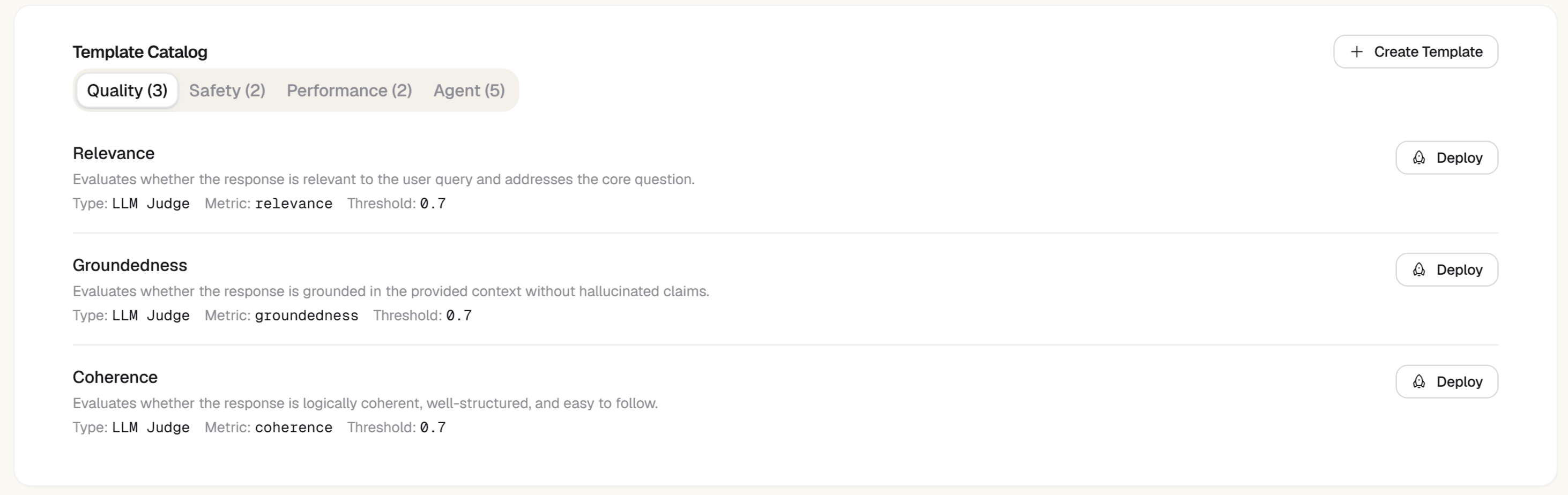
12 Built-In Templates
Pre-built LLM-as-judge templates for the most common quality dimensions: correctness, faithfulness, relevance, toxicity, conciseness, coherence, and more. Each template is configurable per project with custom thresholds.
- Quality: correctness, coherence, completeness, conciseness
- Safety: toxicity, PII leakage detection, harmful content
- RAG-specific: faithfulness (grounded in context?), relevance (answers the question?)
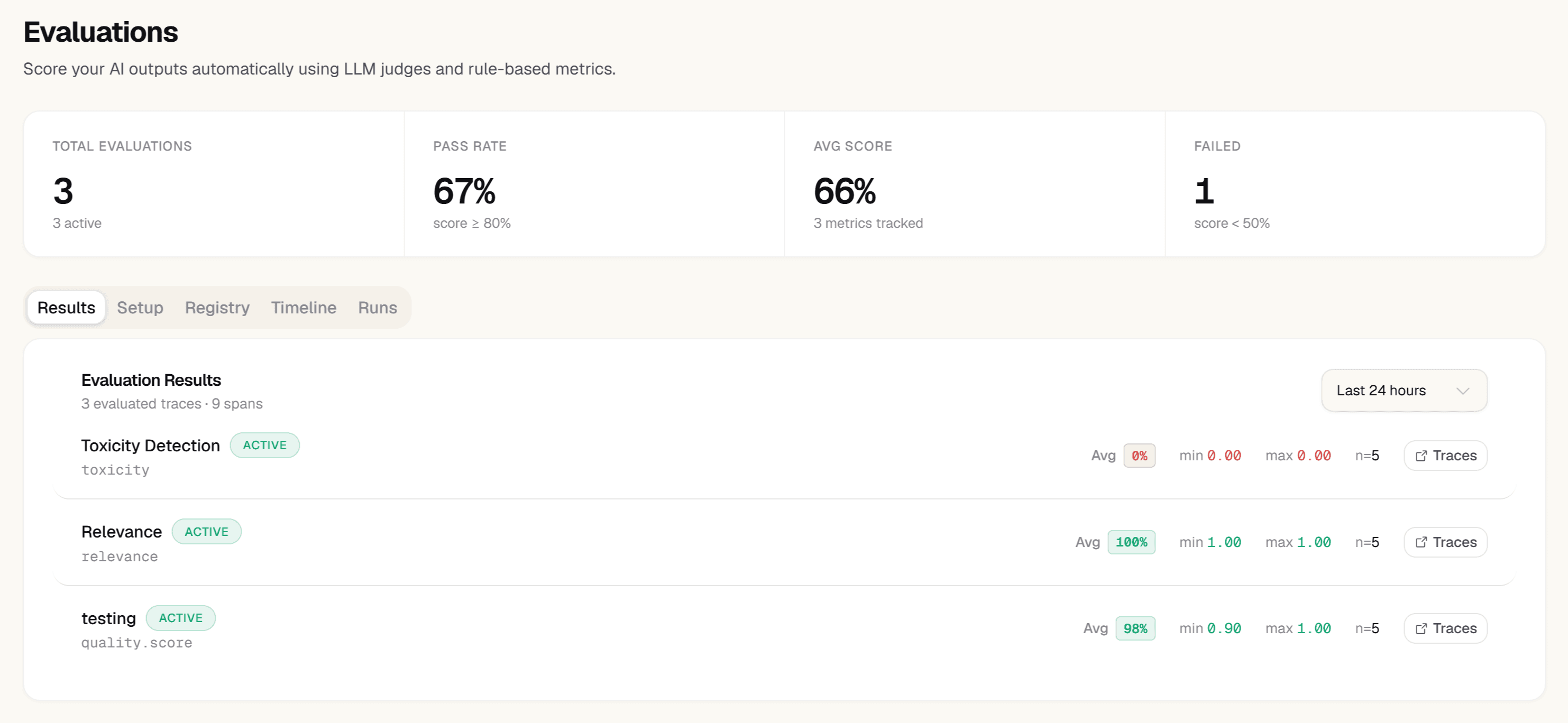
Evaluation Detail & Trends
The evaluation detail view shows per-trace scores with input, output, and the judge's reasoning. Scores trend over time — bucketed by configurable intervals — so you see quality drift as it starts, not weeks later.
- Per-trace view: score, judge reasoning, input, output
- Timeline view: metric scores bucketed by hour, day, or week
- Up to 200 metric keys tracked simultaneously
Manual Eval Runs
Trigger evaluation runs on-demand against a dataset or trace set. Runs execute asynchronously via background worker. Browse full run history with status, aggregate scores, and timing.
- Run against any dataset or trace selection
- Async execution — large runs don't block the UI
- Run history: full list with status (queued, running, completed, failed)
Get started
Set up in under 5 minutes
// Enable auto-evaluators in Project Settings → Evaluations
// Then scores appear on every trace automatically.
// Or attach an eval score manually from your code:
import { Zespan } from '@zespan/sdk';
const lt = new Zespan({ apiKey: process.env.ZESPAN_API_KEY });
await lt.traces.addEvalScore(traceId, {
metric: 'faithfulness',
score: 0.92,
reason: 'Answer matches retrieved context',
});Frequently asked
Which LLM does Zespan use as the eval judge?
The judge model is configurable per evaluator — you can use GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro, or any supported provider. You pay for the judge's tokens at standard provider rates; Zespan doesn't mark up model costs.
Does auto-evaluation add latency to my production traces?
No. Evaluation runs asynchronously after the trace is ingested. It never touches your request path. Your users see no latency from evaluations.
Can I use my own evaluation logic instead of the built-in templates?
Yes. Create custom evaluators with your own metric key, description, and judge prompt. You can also attach eval scores directly from your own code using lt.traces.addEvalScore() — Zespan will store and display them alongside auto-eval scores.
What is faithfulness and why does it matter for RAG?
Faithfulness measures whether the model's answer is grounded in the retrieved context or generated from memory (hallucination). For RAG pipelines, a faithfulness score below your threshold is a signal that retrieved context isn't reaching the model properly or the model is ignoring it.
Can I trigger regression detection when deploying a new prompt?
Yes — this is automatic. When you promote a prompt version to the production label, Zespan runs a background regression check comparing eval scores vs. the previous 14 days. If any evaluator drops >10 percentage points, you get a ZespanPilot notification.
Start free — 10K traces/month, no card needed
Setup takes under 5 minutes. Works with OpenAI, Anthropic, LangChain, and more.