Groq Integration
Drop-in wrapper for the Groq SDK. Every Llama, Mixtral, and Gemma inference call is traced with accurate sub-second latency measurement.
Groq provides ultra-low-latency inference for open models (Llama 3, Mixtral, Gemma, Whisper) via a dedicated LPU inference engine.
Getting Started
Install the SDK
Install @zespan/sdk alongside groq-sdk.
npm install @zespan/sdk groq-sdkWrap the Groq client
Pass your Groq client to wrapGroq(). All chat completion calls are traced with accurate latency measurement.
import Groq from 'groq-sdk';
import { Zespan, wrapGroq } from '@zespan/sdk';
const lt = new Zespan({ apiKey: process.env.ZESPAN_API_KEY });
const groq = wrapGroq(new Groq(), lt);
const completion = await groq.chat.completions.create({
model: 'llama-3.3-70b-versatile',
messages: [{ role: 'user', content: 'Hello' }],
});View traces in Zespan
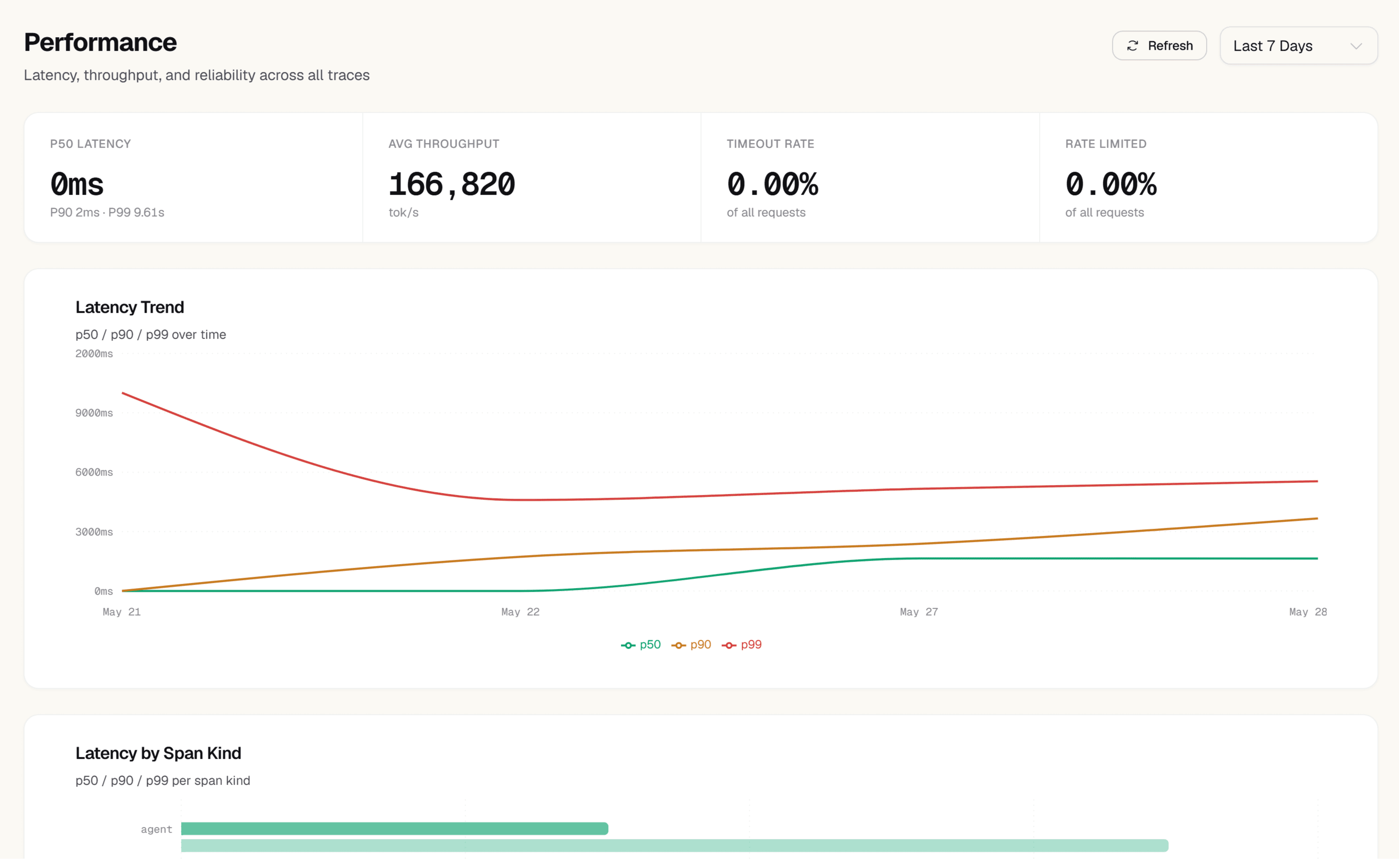
Open Trace Explorer. Groq calls appear with model, token usage, cost, and latency. The Performance view shows Groq's sub-second latency distribution.
What's captured automatically
- Accurate sub-second latency: time-to-first-token and total latency measured precisely
- All Groq models: Llama 3, Mixtral, Gemma, Whisper, and future additions
- Model comparison: compare cost and latency across Groq models in Cost Attribution
- Rate limit tracking: 429 errors attributed with full context
- Audio transcription: Whisper calls traced alongside chat completions
FAQ
Does Zespan capture Groq's fast time-to-first-token accurately?
Yes. The SDK measures time from request start to first token received, which is the meaningful latency number for Groq's streaming completions.
Can I compare Groq vs OpenAI latency in Zespan?
Yes. Filter the Performance view by provider and compare P50/P95/P99 latency across providers and models side by side.
Start for free — 10K traces/month, no card needed
Groq integration works on all plans including the free tier.