Use Case — Customer Support AI
Deploy support agents that stay on-script — and tell you when they don't.
Support AI that leaks PII, shares wrong pricing, or responds off-topic is a trust and compliance risk. Zespan gives you the guardrails and visibility to prevent it.
The problem
Unsafe outputs reach users
Support agents occasionally leak PII, quote wrong prices, or respond to off-topic requests. You find out after the fact, never before.
Quality is hard to measure at scale
CSAT is a lagging indicator. It doesn't tell you which specific responses failed, which conversation caused it, or how often it's happening.
Per-conversation cost is invisible
Some support topics cost 10× more to handle than others. You can't see which — or optimize routing to cheaper models for simpler cases.
How to use Zespan for this
Configure guardrails — PII, toxicity, and topic boundary
Open Project Settings → Guardrails. Add a PII guardrail (action: redact) to strip names, emails, and phone numbers from completions before they're logged. Add a toxicity guardrail (action: block). Add a topic boundary guardrail with your allowed topic list — billing, account, product — to prevent the agent from answering off-topic questions. Test each rule against sample inputs with the live test endpoint before enabling.
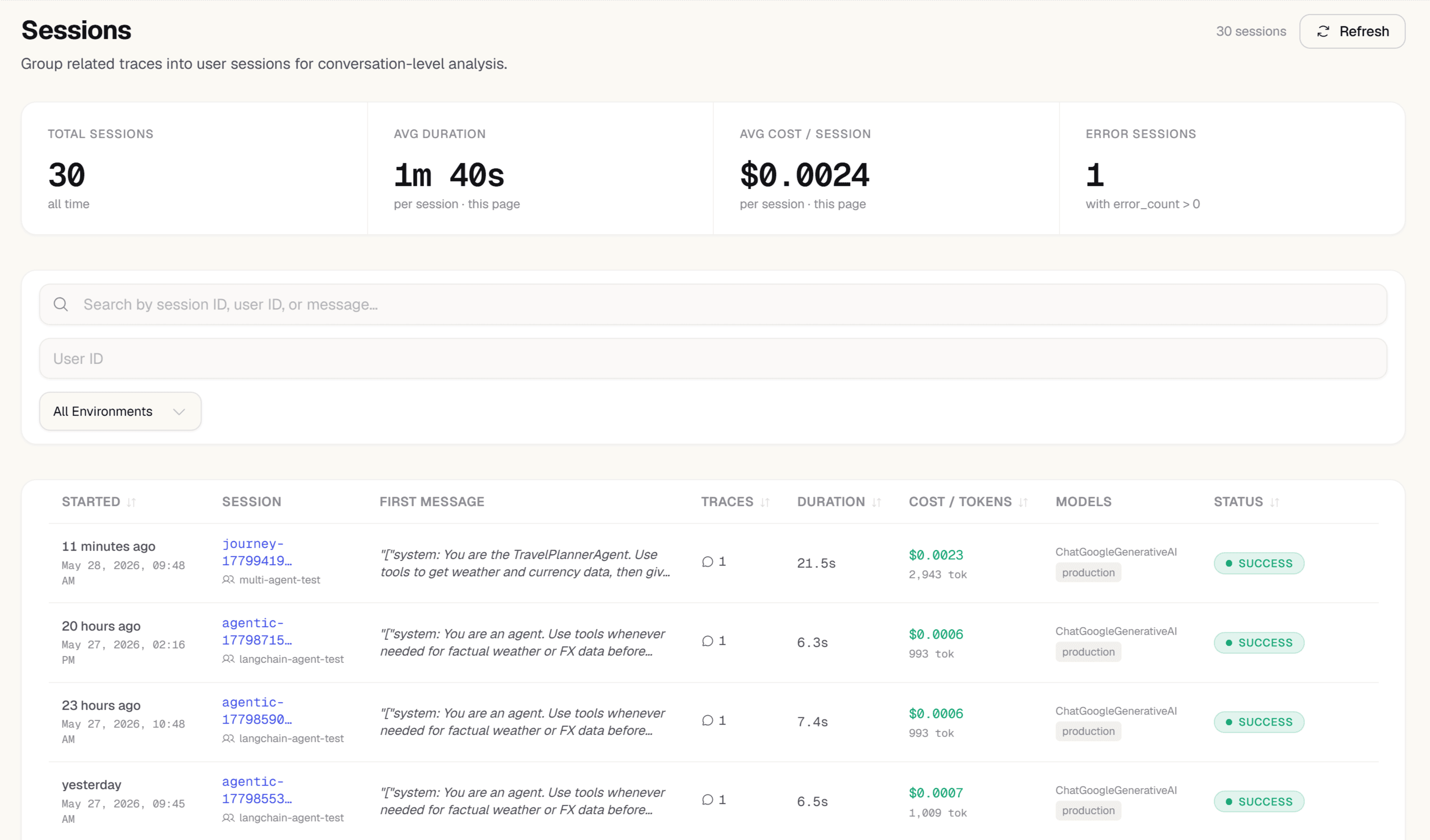
Open Sessions — the full conversation in one view
In the sidebar, open Sessions. Every customer conversation is grouped by session_id — total cost, token count, error count, and a first-message preview per conversation. Click any session to see every exchange in order. Filter by user_id to investigate a specific customer's experience without digging through raw logs.
Check Evaluations — faithfulness at scale
Open Evaluations. Enable the faithfulness auto-evaluator so every support response is scored: did the agent answer from the knowledge base or generate from memory? A faithfulness score trending down over a week signals your knowledge base needs updating or your prompt has drifted. No CSAT survey needed.
Open Cost Attribution — slice by support topic
In Cost → Attribution, switch the dimension to 'operation'. If you tagged LLM calls with the support topic (billing, password-reset, returns), you'll see the cost per topic. Billing disputes might cost 6× more per conversation than password resets. That's your optimization target — better knowledge base coverage or routing to a cheaper model.

Set error and quality alerts — know before escalations happen
Create an alert: error_rate > 3% on your support agent spans, 10-minute window, fire to Slack. Create a second alert linking to the faithfulness eval metric — if average faithfulness drops below 0.75 for a 1-hour window, page the team. These two alerts together catch technical failures and silent quality degradation independently.
Start free — 10K traces/month, no card needed
See every agent decision, tool call, and handoff in production. Setup takes under 5 minutes.
Get started free →